


Manufacturing companies are under pressure to adopt new technologies in order to remain competitive. As the world of product development...

There is no secrets – traditional PLM systems are running on top of relational databases systems. Although I didn’t find...

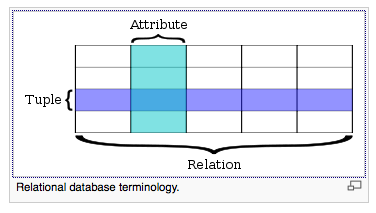
For many years, databases is the most critical element of PLM infrastructure. After all, PLM systems are data management systems...

I think the agreement about importance of the data model among all implementers of PDM / PLM is almost absolute....
Big data is hyping trend these days. Many people is using the term of big data for different purposes and...
It is not unusual to hear about problems with PLM systems. It is costly, complicated, hard to implement and non-intuitive....

I want to talk about an interesting segment of cloud technologies – cloud SQL Database. For the last months, I’ve...
The following article in TechWords “The New FOSS Frontier: The Database Market” drove me to think about PLM and RDBS...