



There’s a classic saying: “If all you have is a hammer, everything looks like a nail.” Most of the time, it’s used to criticize solutions that are too general—applying one tool to every problem, whether it fits or not.
But let’s flip that for a moment.
What if the tool is the data model—and what we actually need is a better hammer? Not to solve everything in the same way, but to solve data problems intelligently and intentionally, with the right level of abstraction and flexibility. Especially in product lifecycle management (PLM) software, where product data and product lifecycle are built around data—parts, structures, revisions, changes, configurations, suppliers, documents, and more—it’s the data model that ultimately shapes how a system behaves.
Think of different business process, product development processes, document management, and even business system for entire product lifecycle – what data model is needed for these systems to make them improve product development processes, product lifecycle management, quality management, collaboration and many other disciplines for engineering teams and manufacturing companies.
And yet, despite all the changes in product development, engineering, and digital transformation, most of product data management and PLM software platforms are still operating with the same hammer they had 30 years ago.
Let’s talk about that. Here is a diagram that represents how data modeling worked in different generations of PDM/PLM systems.
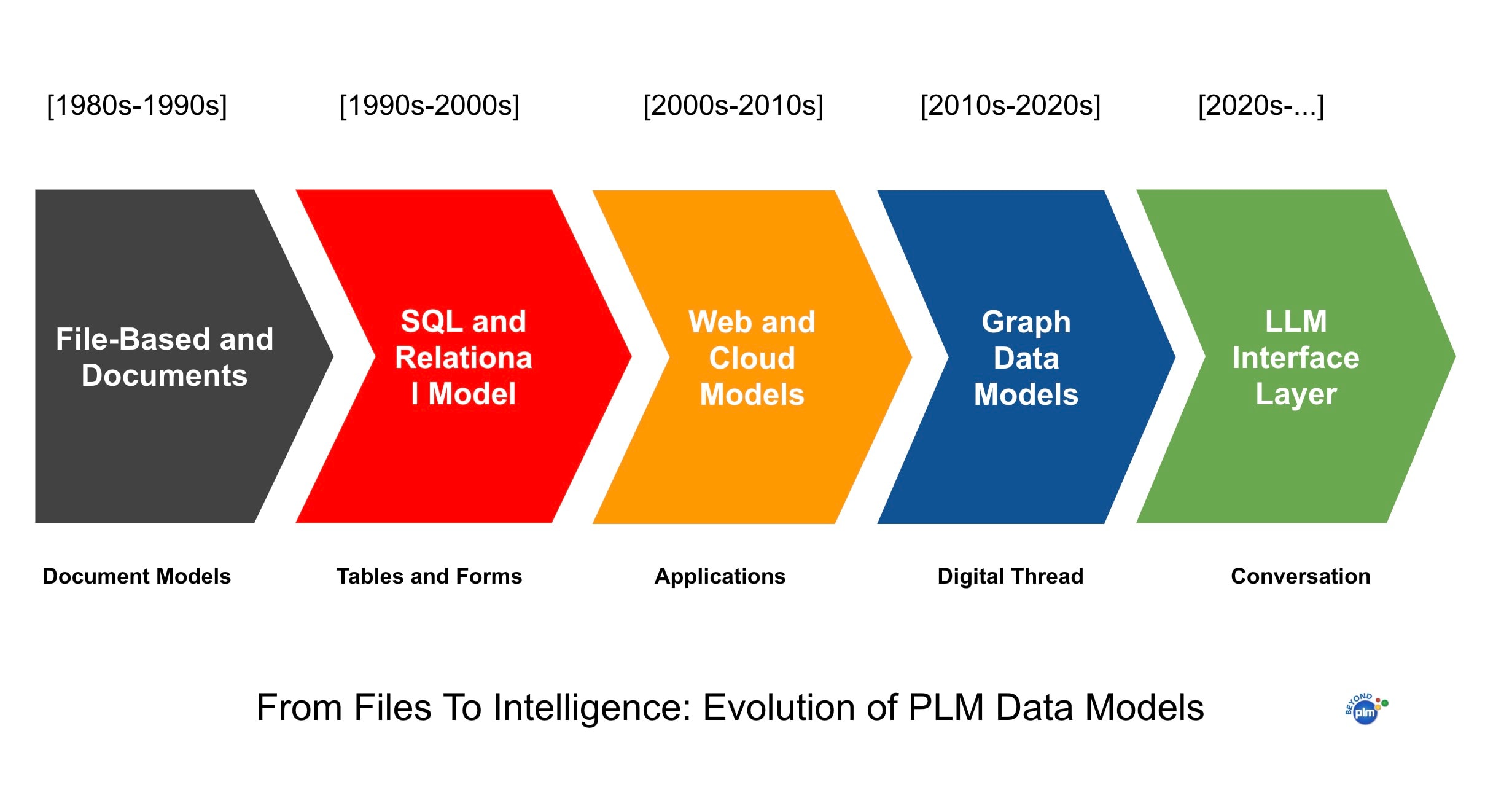
In my article today, I want to talk about the evolution of data models in PLM software.
From Files to SQL: The Data Model Legacy
You might remember an old PDM/PLM data management decision from 1990s diagram I once shared:
- If it looks like a file, it’s CAD or Microsoft Office.
- If it doesn’t, it’s a SQL database.
A few decades, most PDM and PLM software could be categorized pretty simply. If it looked like a file, it was probably some flavor of CAD or Microsoft Office. If it didn’t, then it was likely running on a SQL database somewhere underneath.
This simple dichotomy represented how most business software operated. For decades, data models were shaped by file metaphors or rigid relational schemas. SQL—born in the 1970s—became the default way to manage structured data by the 1980s and 90s.
That distinction held up for a long time. SQL brought consistency and structure to data when businesses desperately needed both. It was a great way to model records and transactions, and it gave birth to everything from ERP to traditional PLM.
It brought standardization, reliability, and consistency to enterprise systems. And it worked—until it didn’t. But the world moved on. The internet happened. Cloud computing happened. And product development became way more complex. As software systems began to support new business models, more dynamic user experiences, and more distributed environments, the limits of rigid SQL schemas started to show.
The Cambrian Explosion of Data Models
The early 2000s, powered by the rise of the web and cloud computing, marked a turning point. Developers needed more flexibility and web systems were not limited by the approvals of IT and DBAs. The database world responded with a Cambrian explosion of new models:
- Key-value stores for ultra-fast access
- Document databases for semi-structured content
- Graph databases for complex relationships
- Wide-column stores for big data analytics
- Many other variations of database tech…
We entered what I like to call the “Cambrian explosion” of data models. Developers weren’t satisfied with just one model anymore—they started choosing the right tool for the job. Need fast lookup? Use key-value. Need to store messy documents? Use JSON in a document store. Need to model complexity? That’s where graph databases came in.
It’s a world where data modeling became intentional again, not accidental. And the term “polyglot persistence” started to make its way into the modern developer vocabulary—essentially meaning: don’t try to force every problem into the same database model. Use what fits. And use more than one if needed.
This era gave rise to polyglot persistence—the idea that no single database is optimal for all use cases. Instead, each microservice or component in a system can choose the most appropriate data model and persistence mechanism.
Even if you’ve never heard the term polyglot persistence, chances are you’re already living in it. Web-scale systems and consumer apps have embraced this model for years.
Unfortunately, traditional PLM software never really made that jump and has been slow to adapt new data modeling practice.
PLM’s Data Problem: One Hammer for Every Nail
Most PLM platforms today still rely heavily on relational databases. Some might have slightly more flexible architectures, but underneath the hood, you’ll often find the same rows and columns, the same schemas designed decades ago, and the same rigid modeling approach.
Most legacy PLM systems still live in a SQL-first (or file-first) world. Their architectures were designed when data modeling meant locking yourself into a schema for a decade. That rigidity might have made sense in the 1990s—but it’s a liability today.
That’s a problem—not just because it’s old, but because it doesn’t reflect how products are actually built and managed today.
Modern products are complex. They include software, electronics, mechanical parts, and cloud services. They change constantly. They are designed by teams that work across time zones and companies. And the relationships between all these parts—components, versions, suppliers, processes—are anything but flat. They’re rich, multi-dimensional, and deeply interconnected.
Trying to model that with just SQL is like trying to draw a 3D object using only 2D lines. You can get some of the structure, but you miss the depth, the nuance, the actual relationships.
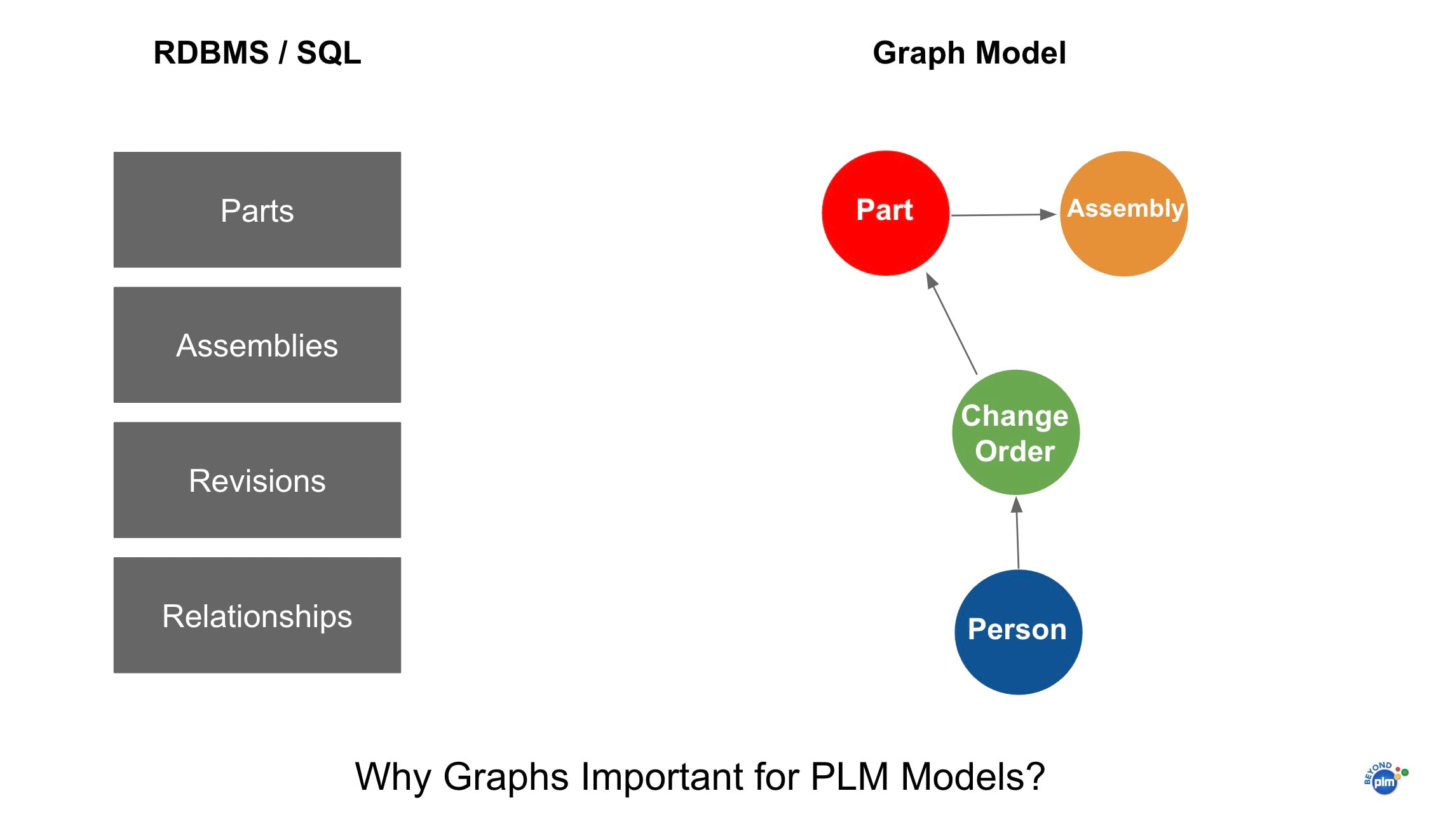
This is where graph data models start to shine. Why? Because modern products are more:
- Complex (multi-disciplinary, software-integrated)
- Dynamic (frequent changes, modular designs)
- Connected (supply chains, ecosystems, IoT)
To support this reality, PLM software needs to be as flexible and adaptive as the products it helps manage. And that starts with the data model.
If there’s one data model that truly fits the nature of PLM, it’s graphs. And not just because they’re trendy—because they actually mirror how engineers and companies think about their products.
Graphs let you model relationships as first-class citizens. You’re not just tracking items and revisions—you’re capturing how things connect. A part is used in an assembly. That assembly is part of a product configuration. A design is approved by someone. A change affects multiple downstream dependencies.
And when you want to understand the impact of a change, or navigate a digital thread that spans design, supply chain, and quality—you don’t want to write 12 SQL joins and hope for the best. You want to follow the connections. You want to walk the graph.
This is where PLM systems need to evolve. The relationships between things are no longer secondary—they are the system. Graph databases offer a natural, flexible, and scalable way to represent this complexity. They don’t force you to define every relationship in advance. They allow your data model to grow with your business and your product.
That kind of flexibility is essential. Products are not static. Neither should your data model be.
And Then Came LLMs
Now, let’s talk about the elephant in the room—Large Language Models.
There’s a lot of buzz out there about how LLMs will replace business applications. People say we won’t need databases or software at all—just ask the AI, and it will give you answers. I think that’s overly optimistic.
LLMs are powerful tools, no doubt. They’re great at interpreting natural language, summarizing content, and generating insights from unstructured data. Will they become a database for PDM/PLM software? They’re not optimized for precision queries, structured data, or transactional integrity. You don’t use an LLM to manage a structure of bill of materials or to enforce revision control.
At the same time, we use LLM models and conversational interface more and more often. LLMs can become an intelligent interface layer—helping people interact with structured systems more naturally. Instead of writing queries or navigating complex UIs, users can just ask questions, and the LLM can translate those into the right graph or SQL queries behind the scenes.
In my view, it is a big deal. Because it means we can make powerful systems more usable, without sacrificing the integrity of the underlying data. In my view, LLMs won’t replace SQL or graph databases. But they will sit on top of them—and make them smarter, more accessible, and more human.
Where We’re Headed: SQL, Graph, and LLMs
So what’s next? I believe that three data models will define the future of PLM:
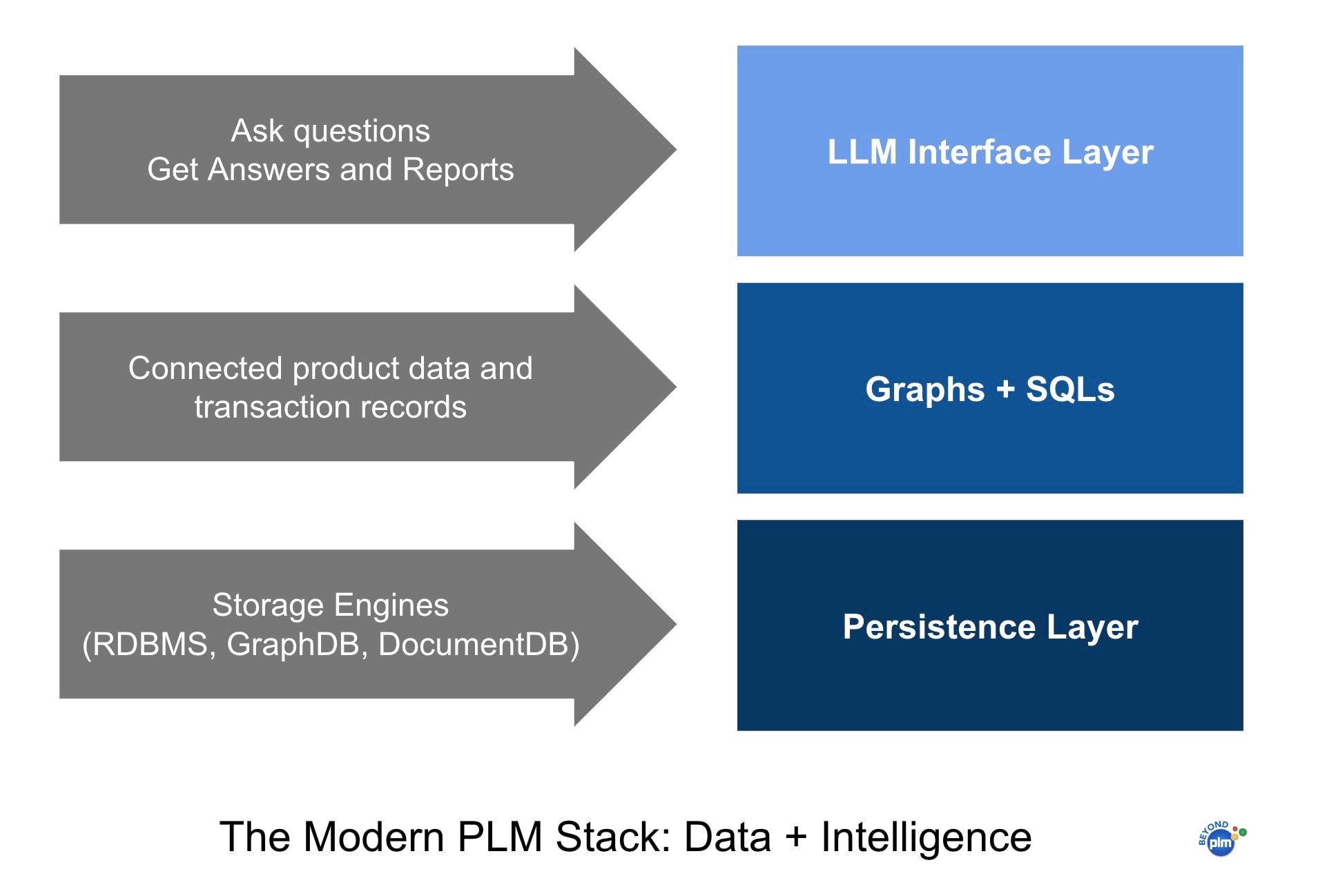
1. SQL – The structured workhorse
Relational databases aren’t going away. They’re still excellent for transactional data, tabular records, and consistent schemas. SQL is great when you know exactly what structure you need and can enforce it—perfect for parts, change orders, cost tables, and more.
2. Graph Databases – The relational revolution
Graphs shine when relationships are central—think assemblies, part dependencies, configurations, and digital threads. They model complexity in a natural, scalable way. The flexibility of graph structures allows for evolving schemas, which is crucial for PLM use cases like variant management, multi-level BOMs, or process flows.
3. LLMs (Large Language Models) – The conversational layer
There’s a lot of hype around LLMs replacing business applications entirely. I think that’s too visionary. LLMs are not data stores or query engines—they’re interfaces. They’re great at generating queries, summarizing content, or answering questions. But they aren’t optimized for data integrity, structured querying, or transactional control. LLMs won’t replace SQL or graph models—but they will complement them.
Imagine asking your PLM system:
“What are the alternate components approved for this assembly revision in Germany?”
The LLM interprets the request, translates it to a graph query, and retrieves the data. That’s the future—not an LLM storing your BOMs, but enabling intelligent access to structured systems.
A Recipe, Not a Silver Bullet
If you’ve made it this far, here’s the analogy I like to use: building a PLM system is a lot more like running a kitchen than running a factory.
There’s no “best” ingredient. There’s only the right combination of ingredients, chosen with care, prepared with precision, and adapted to the dish you’re trying to make.
In PLM, the data model is your ingredient list. You need structure (SQL), relationships (graph), and intelligence (LLMs) all working together. You don’t want to be stuck with one hammer. You want a toolkit.
And most importantly, you want a system that adapts with your product—not one that locks you into decisions made years ago.
The future of PLM isn’t going to be built on a single data model. It’s going to be built on a smart combination of them—each playing its role, each solving the problem it’s best at solving.
SQL will stay. Graphs will grow. LLMs will help us interact with all of it in smarter ways.
We need platforms that are:
- Composable – Mix and match services and models
- Open – Connect seamlessly to external systems
- Flexible – Evolve with product complexity
- Semantic – Understand relationships beyond rows and columns
Building a PLM system is like preparing a complex meal—there’s no best ingredient, only the right ingredients for the dish. SQL, Graph, and LLMs each bring unique strengths, and the art of PLM development lies in knowing how to combine them.
What is my conclusion?
The job of today’s PLM developers and architects is to stop thinking about the database as an afterthought—and start thinking about the data model as the foundation. Because in the end, everything in PLM is data. And the quality of your data model defines the quality of everything else.
So let’s stop using the same old hammer—and start crafting better ones.
How to invent a new data hammer for a digital PLM era? PLM software is long overdue for a data model rethink. As product complexity grows and digital thread strategies evolve, sticking with a single, rigid model won’t cut it.
We need a new “digital data hammer”—not to treat every problem the same, but to give us the power to solve any problem with the right tool. Data is at the center of this shift, and the developers of tomorrow’s PLM systems will win by choosing—and combining—the right data abstractions for the job.
The future isn’t monolithic. It’s multi-model. And it’s already here.
Just my thoughts…
Best, Oleg
Disclaimer: I’m the co-founder and CEO of OpenBOM, a digital-thread platform providing cloud-native collaborative services including PDM, PLM, and ERP capabilities. With extensive experience in federated CAD-PDM and PLM architecture, I’m advocates for agile, open product models and cloud technologies in manufacturing. My opinion can be unintentionally biased





