




It’s time to ask yourself: is Excel holding your organization back? Over the last few years, I’ve been talking to many organizations of different sizes – small and large about data management, enterprise systems such as PLM and ERP and about what can become the next step of enterprise PLM development. The usual perspective of companies – doesn’t matter how good enterprise systems are doing, companies will be naturally gravitating towards spreadsheet-like data management to solve problems because it initially simpler and doesn’t require a big strategic decisions. I discussed it with many colleagues and friends. Many of them told that engineers will always export data to Excel to communicate and solve multiple problems that exist in any small and large manufacturing organization. Existing data paradigm is that any product data can be represented by “files” (CAD or derivatives) and “spreadsheets” that can be using an old Excel file or modern variations of spreadsheets (Google spreadsheets, or specialized ‘new’ types of sheets – AirTables, SmartSheets, etc.). What can change the approach?
The Excel Dilemma
We are in the era of data-driven decision-making. Everyone will agree with you that data is the most important organizational asset. At the same time, many enterprise organizations are still heavily reliant on Excel files scattered across various departments. While Excel has been a trusted tool for decades, it’s time to question whether it’s holding your company back from its true potential.
Excel has its merits, but let’s face it: it’s become a problem for many companies. Here are some challenges for Excel driven business I captured during my OpenBOM journey of transforming organizations from using Excel and adopting online data management service such as OpenBOM.
- Data Disarray: Different people and departments maintain their own Excel files, leading to data chaos and inconsistencies. Your organization is trapped in a web of data silos. Engineers export data to Excel part lists. Procurement is using “another Excel” for their purchase orders.
- Version Nightmares: Keeping track of multiple Excel versions is a logistical headache. Errors are inevitable, and decisions may be based on outdated information. I’ve seen companies using name+ver logic stored in Google Drive and other storages.
- Integration Stalemate: Excel files are standalone entities, hindering seamless integration of data from various sources and departments. Collaboration is stifled. Data cannot be semantically identified in Excel, which leads to chaos.
- Accessibility Obstacles: Sharing and accessing Excel files can be cumbersome, especially for remote teams. Your workforce is shackled to their desks, unable to harness the power of modern remote work. Sharing Excel data between organizational departments, suppliers and contractors is crazy inefficient and still used by companies that cannot figure out a “better way”.
What can be done to turn companies away from Excel? What can prevent people and entire organizations away from from grabbing data and saving it in spreadsheet files to be used later?
Deficiency of Vertical Enterprise Systems
For the last 20 years, the trajectory of all enterprise systems (PDM, PLM, ERP, MES, CRM) was heavily moving towards vertically integrated models. The idea of vertical integration promised the best outcome – a single source of responsibility, ensuring seamless integration, and optimized processes. Also, vertical integration of enterprise systems is very well aligned with enterprise business models of “data locking” and using it to expand the presence and upsell more products. We can see how vertical systems used to automate business processes in product lifecycle management, supply chain management, ERP/MRP systems and business decisions related multiple vertical industries in engineering and manufacturing.
Vertical systems are offering many advantages such as centralize database system to collect information and eliminate siloes, data integration, automatic data transfer between departments and users without mapping and translations, collaboration between user groups and seamless access everywhere. Where is the problem?
The main problem is complexity. It is impossible to bring everyone and everything into a single system. The reality of the data landscape and data silos makes impossible for companies to start from a “clean sheet”. So, companies live with multiple systems, many of them are legacy systems. Companies spent millions of dollars to implement these systems, complexity of these systems is skyrocketing and the replacement is not obvious and easy. Integrations cost tons of money (not without profit to service organizations). Which leaves companies without obvious decision with the problem of data management and ‘temporarily’ Excel patches.
Is inefficient data management a problem?
What problem are we trying to solve? The definition of the problem can help to zoom out and to see the current status quo from the business perspective rather than from a standpoint of people trying to struggle with the decisions of how map attributes between multiple systems, arguing about different business practices of managing parts, BOMs, effectivities, form-fit-functions, release processes in the complex enterprise data management mess.
Here is my take. There are two fundamental problems in every manufacturing company related to data – (1) efficiency of data management operations and processes to ensure companies not duplicating data, manually copy it from place to place and having a single source of truth; (2) effectiveness of decision making process using data ensuring that companies will be making right decisions based on the information- making right design decisions based on the historical data records, optimizing product cost, working with right suppliers, and brining customer input in the design and operation.
On top of these two problems, all manufacturing enterprises (and not only enterprises) are experiencing a growing level complexity related to data management in everything – complex design (mechanical, electronics, software), complex supply chain management, configurable products and different manufacturing options, complexity of maintenance and support.
How to solve these two problems and offer to enterprises a better way? The problem of Excel existss in the enterprise organizations for a reason. Although existing highly vertically integrated PLM platfroms provide a solution to support fundamental isolated problem needs, they have 3 fundamental problems:
- Substantial integration gaps and complexity related to integrations with other enterprise platforms (PLM-ERP integrations is an example where only discussion about mapping between platform can trigger massive debates)
- Capturing intent and knowledge rather then outcome. Those enterprise platforms lose a lot of data information during the design, planning, manufacturing and maintenances phases of product lifecycle.
- Lack of efficient data management and integration across value chain (design contractors, suppliers, customers, partners), which causes these systems lose even more valuable information.
How to solve these problem and offer a better way and preserving the value and investment in existing systems and processes?
Knowledge Graph and AI-enabled PLM services
Complex data management requires a better model to manage data. You can manage a simple part list in Excel and store a dozen of CAD files in a folder. But when it comes to the level of complexity we can see in modern manufacturing enterprises, we need to consider using different data models to describe all dependencies, constraints, variants, manufacturing and supply chain options, customer requirements and maintenance operation.
Graph model, knowledge graph and network models presents a promising options to manage comlpex data to capture large amount of Excels, combining this data with information captured from existing enterprise silos (eg. PDM, PLM, ERP, CRM, etc) and turning this data into knowledge and source of data for generative AI algorithms. The explosive growth of ChatGPT and other transformer based models demonstrated the opportunity to capture knowledge and produce a reasonable content and data reuse. Here is an example of my chatGPT sessions asking to generate a bill of materials for electrical bike (you can try it by yourself):
- Frame: Electric bike frame ($150 – $500). Supplier: Local bike shops or online retailers
- Motor: Hub motor ($200 – $400). Supplier: Bafang, MXUS, or Golden Motor
- Battery: Lithium-ion battery (48V, 15-20Ah) ($300 – $600). Supplier: Samsung, Panasonic, or LG cells with a custom battery builder or electric bike retailer
- Controller: Brushless motor controller ($50 – $150). Supplier: Ebike kit retailers or online stores
- Throttle/Pedal Assist: Twist or thumb throttle, PAS ($20 – $50). Supplier: Ebike kit retailers or online stores
- Display/Controls: LCD or LED display ($50 – $150). Supplier: Ebike kit retailers or online stores
- Charger: Battery charger ($30 – $80). Supplier: Ebike kit retailers or online stores
- Brakes: Hydraulic or mechanical disc brakes ($50 – $150). Supplier: Shimano, SRAM, or Tektro
- Wheels/Tires: 26″ or 27.5″ wheels with e-bike tires ($100 – $300). Supplier: Local bike shops or online retailers
- Suspension: Front suspension fork (optional) ($150 – $400). Supplier: RockShox, Fox, or Suntour
- Drivetrain: Chain, chainring, cassette, derailleur (if not included) ($50 – $150). Supplier: Local bike shops or online retailers
- Lights: Front and rear lights ($20 – $100). Supplier: Various bike accessory stores
- Accessories: Fenders, kickstand, bell, bottle holder (optional) ($20 – $50). Supplier: Local bike shops or online retailers
- Labor/Assembly: Labor costs if not assembling it yourself (Varies)
- Miscellaneous: Cables, connectors, zip ties ($20 – $50). Supplier: Local hardware stores or online retailers
From my conversations with PLM vendors, many of them are curious about these examples and what does it mean for their vertical PLM platforms.I found the capabilities of transformer models fascinating and the ability to capture knowledge and information from an existing corpus of data. Transformer machine learning models are very interesting and ChatGPT broke the ice of adoption in the market providing to a large group of users an easy way to interact with artificial intelligence capabilities of these models.
Here is the next gap to solve? The outcome above is created from a large corpus of data captured by OpenAI from public internet data sources. Companies won’t share their data with public models. Companies will be looking how to solve this problem based on their information located in different data sources and represented differently then public internet sources. Privacy and IP protection is important. How to get a useful transformer model from capturing enterprise data is a problem to solve.
The question of how to contextualize transformer models and to provide a way to capturing information from massive amount of data in enterprise systems and even bigger amount of information stored in proprietary data sources, Excels and other files in the enterprise organization, suppliers and contractors. It requires a different model. This is where knowledge graph model can help.
Earlier this year, at PI DX 2023 event in Atlanta, I discussed the opportunity to harness the power of the data using graph data models and creating product knowledge graph using modern graph database technologies and flexible interfaces allowing to collect data from multiple data sources. Check my presentation at the event in the following article – Discussing the Power of Knowledge Graphs and AI in PLM at PI DX USA 2023.
Here is an example of OpenBOM graph-based architecture developed to provide a way to collect information from multiple data sources. The main differentiator of this model is flexible data model and usage of graph databases.
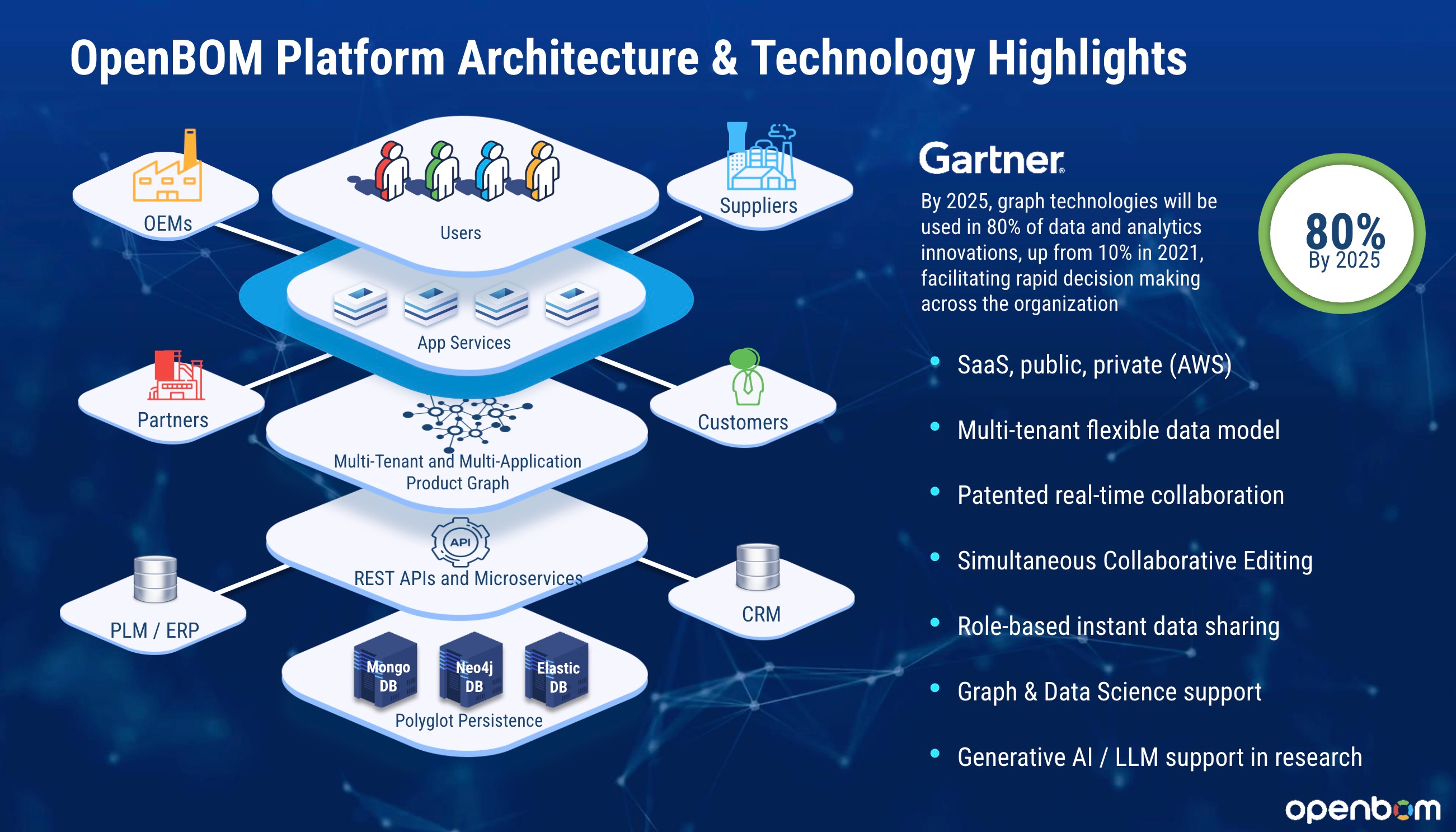
Here is another example of graph data model developed by Prof. Dr. Martin Eigner Michael Pfenning, Nico Kasper and Immanuel Pschied.

Another example of supply chain analysis performed using graph model graph data science queries in Neo4j. Check my article from Graph Data Summit by Neo4j in Boston earlier this year. The slide below was captured from one of the presentations of Joe Fijak, Global EVP/COO, Ennoconn Corporation, and Gemini Data. What was remarkable is the story of how graph technologies provided by Neo4j can help to solve problems of supply chain analysis using graph models.
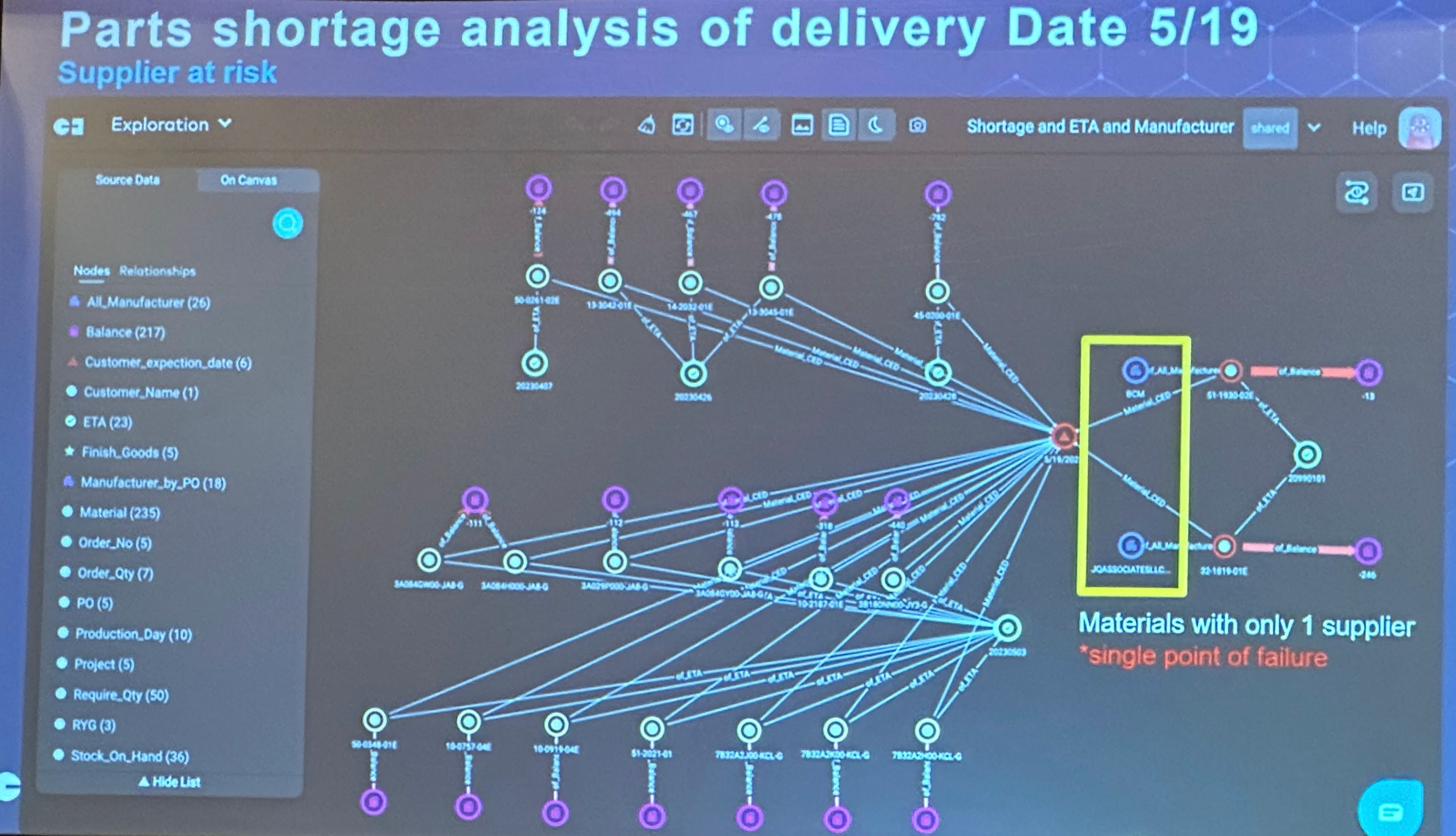
I hope you can see where I’m going with the idea of creation of flexible graph data models to provide solutions to problems that current enterprise systems cannot solve and technologies to capture product knowledge.
What is my conclusion?
Manufacturing companies need to find a better way to capture and manage information. There is a way of bridging existing Excel/File/Folder/Email paradigm for data management and highly vertical and isolated enterprise monolithic systems to provide flexible data model and system to capture information and knowledge that can be used to accelerate product development (efficiency) and empower decision making (effectiveness). Altogether can provide a better way to integrate information and streamline business processes to support complexity of modern products and business transformation. These models is a place digital thread begins and a source of information for machine learning algorithms and predictive analytics. It is a way to support natural language processing in user experience and integrate real time data from multiple systems into decision making process. Just my thoughts…
Best, Oleg
Disclaimer: I’m co-founder and CEO of OpenBOM developing a digital-thread platform with cloud-native PDM & PLM capabilities to manage product data lifecycle and connect manufacturers, construction companies, and their supply chain networks. My opinion can be unintentionally biased.
Best, Oleg








